mirror of https://github.com/go-gitea/gitea
Fixes #27605: inline math blocks can't be preceeded/followed by alphanumerical characters (#30175) (#30250)
Backport #30175 by @jmlt2002 - Inline math blocks couldn't be preceeded or succeeded by alphanumerical characters due to changes introduced in PR #21171. Removed the condition that caused this (precedingCharacter condition) and added a new exit condition of the for-loop that checks if a specific '$' was escaped using '\' so that the math expression can be rendered as intended. - Additionally this PR fixes another bug where math blocks of the type '$xyz$abc$' where the dollar sign was not escaped by the user, generated an error (shown in the screenshots below) - Altered the tests to accomodate for the changes Former behaviour (from try.gitea.io):  Fixed behaviour (from my local build): 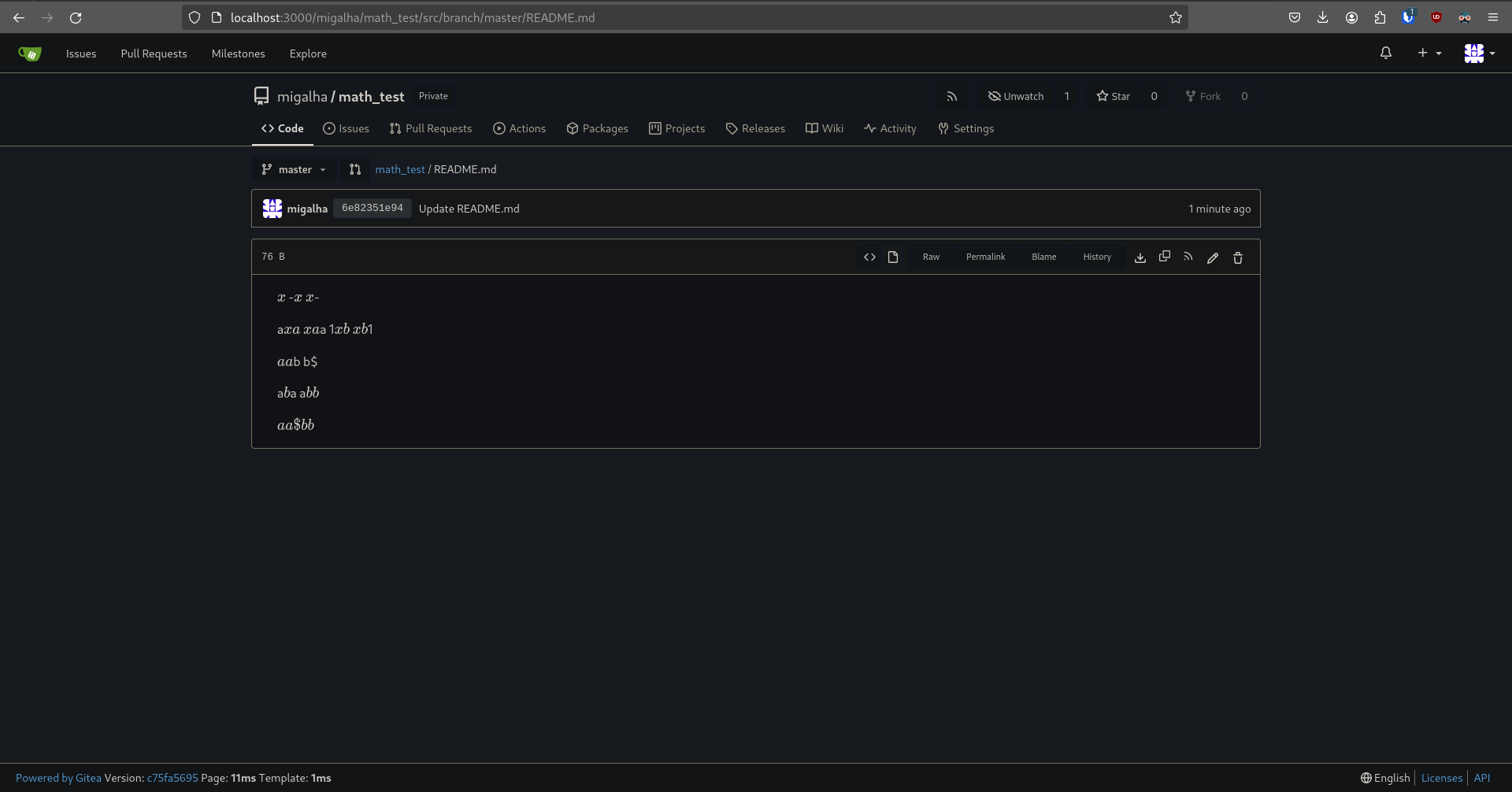 (Edit) Source code for the README.md file: ``` $x$ -$x$ $x$- a$xa$ $xa$a 1$xb$ $xb$1 $a a$b b$ a$b $a a$b b$ $a a\$b b$ ``` Signed-off-by: João Tiago <joao.leal.tintas@tecnico.ulisboa.pt> Co-authored-by: João Tiago <114936010+jmlt2002@users.noreply.github.com>pull/30264/head^2
parent
9f2a1a55e6
commit
5123ed3191
Loading…
Reference in new issue