To make the markup package easier to maintain:
1. Split some go files into small files
2. Use a shared util.NopCloser, remove duplicate code
3. Remove unused functions
Follow #32383
This PR cleans up the "Deadline" usages in templates, make them call
`ParseLegacy` first to get a `Time` struct then display by `DateUtils`.
Now it should be pretty clear how "deadline string" works, it makes it
possible to do further refactoring and correcting.
Closes https://github.com/go-gitea/gitea/issues/30296
- Adds a DB fixture for actions artifacts
- Adds artifacts test files
- Clears artifacts test files between each run
- Note: I initially initialized the artifacts only for artifacts tests,
but because the files are small it only takes ~8ms, so I changed it to
always run in test setup for simplicity
- Fix some otherwise flaky tests by making them not depend on previous
tests
Fix#28121
I did some tests and found that the `missing signature key` error is
caused by an incorrect `Content-Type` header. Gitea correctly sets the
`Content-Type` header when serving files.
348d1d0f32/routers/api/packages/container/container.go (L712-L717)
However, when `SERVE_DIRECT` is enabled, the `Content-Type` header may
be set to an incorrect value by the storage service. To fix this issue,
we can use query parameters to override response header values.
https://docs.aws.amazon.com/AmazonS3/latest/API/API_GetObject.html
<img width="600px"
src="https://github.com/user-attachments/assets/f2ff90f0-f1df-46f9-9680-b8120222c555"
/>
In this PR, I introduced a new parameter to the `URL` method to support
additional parameters.
```
URL(path, name string, reqParams url.Values) (*url.URL, error)
```
---
Most S3-like services support specifying the content type when storing
objects. However, Gitea always use `application/octet-stream`.
Therefore, I believe we also need to improve the `Save` method to
support storing objects with the correct content type.
b7fb20e73e/modules/storage/minio.go (L214-L221)
This contains two backwards-compatible changes:
* in the lfs http_client, the number of lfs oids requested per batch is
loaded from lfs_client#BATCH_SIZE and defaulted to the previous value of
20
* in the lfs server/service, the max number of lfs oids allowed in a
batch api request is loaded from server#LFS_MAX_BATCH_SIZE and defaults
to 'nil' which equates to the previous behavior of 'infinite'
This fixes#32306
---------
Signed-off-by: Royce Remer <royceremer@gmail.com>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
This introduces a new flag `BlockAdminMergeOverride` on the branch
protection rules that prevents admins/repo owners from bypassing branch
protection rules and merging without approvals or failing status checks.
Fixes#17131
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Co-authored-by: Giteabot <teabot@gitea.io>
These settings can allow users to only display the repositories explore page.
Thanks to yp05327 and wxiaoguang !
---------
Co-authored-by: Giteabot <teabot@gitea.io>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
close#25833
Currently, the information for "requested_reviewers" is only included in
the webhook event for reviews. I would like to suggest adding this
information to the webhook event for "PullRequest comment" as well, as
they both pertain to the "PullRequest" event.
Also, The reviewer information for the Pull Request is not displayed
when it is approved or rejected.
This is a large and complex PR, so let me explain in detail its changes.
First, I had to create new index mappings for Bleve and ElasticSerach as
the current ones do not support search by filename. This requires Gitea
to recreate the code search indexes (I do not know if this is a breaking
change, but I feel it deserves a heads-up).
I've used [this
approach](https://www.elastic.co/guide/en/elasticsearch/reference/7.17/analysis-pathhierarchy-tokenizer.html)
to model the filename index. It allows us to efficiently search for both
the full path and the name of a file. Bleve, however, does not support
this out-of-box, so I had to code a brand new [token
filter](https://blevesearch.com/docs/Token-Filters/) to generate the
search terms.
I also did an overhaul in the `indexer_test.go` file. It now asserts the
order of the expected results (this is important since matches based on
the name of a file are more relevant than those based on its content).
I've added new test scenarios that deal with searching by filename. They
use a new repo included in the Gitea fixture.
The screenshot below depicts how Gitea shows the search results. It
shows results based on content in the same way as the current version
does. In matches based on the filename, the first seven lines of the
file contents are shown (BTW, this is how GitHub does it).

Resolves#32096
---------
Signed-off-by: Bruno Sofiato <bruno.sofiato@gmail.com>
This PR addresses the missing `bin` field in Composer metadata, which
currently causes vendor-provided binaries to not be symlinked to
`vendor/bin` during installation.
In the current implementation, running `composer install` does not
publish the binaries, leading to issues where expected binaries are not
available.
By properly declaring the `bin` field, this PR ensures that binaries are
correctly symlinked upon installation, as described in the [Composer
documentation](https://getcomposer.org/doc/articles/vendor-binaries.md).
X-Forwarded-Host has many problems: non-standard, not well-defined
(X-Forwarded-Port or not), conflicts with Host header, it already caused
problems like #31907. So do not use X-Forwarded-Host, just use Host
header directly.
Official document also only uses `Host` header and never mentioned
others.
Close#31801. Follow #31761.
Since there are so many benefits of compression and there are no reports
of related issues after weeks, it should be fine to enable compression
by default.
This will allow instance admins to view signup pattern patterns for
public instances. It is modelled after discourse, mastodon, and
MediaWiki's approaches.
Note: This has privacy implications, but as the above-stated open-source
projects take this approach, especially MediaWiki, which I have no doubt
looked into this thoroughly, it is likely okay for us, too. However, I
would be appreciative of any feedback on how this could be improved.
---------
Co-authored-by: Giteabot <teabot@gitea.io>
Replace #32001.
To prevent the context cache from being misused for long-term work
(which would result in using invalid cache without awareness), the
context cache is designed to exist for a maximum of 10 seconds. This
leads to many false reports, especially in the case of slow SQL.
This PR increases it to 5 minutes to reduce false reports.
5 minutes is not a very safe value, as a lot of changes may have
occurred within that time frame. However, as far as I know, there has
not been a case of misuse of context cache discovered so far, so I think
5 minutes should be OK.
Please note that after this PR, if warning logs are found again, it
should get attention, at that time it can be almost 100% certain that it
is a misuse.
https://github.com/go-fed/httpsig seems to be unmaintained.
Switch to github.com/42wim/httpsig which has removed deprecated crypto
and default sha256 signing for ssh rsa.
No impact for those that use ed25519 ssh certificates.
This is a breaking change for:
- gitea.com/gitea/tea (go-sdk) - I'll be sending a PR there too
- activitypub using deprecated crypto (is this actually used?)
Follow #31908. The main refactor is that it has removed the returned
context of `Lock`.
The returned context of `Lock` in old code is to provide a way to let
callers know that they have lost the lock. But in most cases, callers
shouldn't cancel what they are doing even it has lost the lock. And the
design would confuse developers and make them use it incorrectly.
See the discussion history:
https://github.com/go-gitea/gitea/pull/31813#discussion_r1732041513 and
https://github.com/go-gitea/gitea/pull/31813#discussion_r1734078998
It's a breaking change, but since the new module hasn't been used yet, I
think it's OK to not add the `pr/breaking` label.
## Design principles
It's almost copied from #31908, but with some changes.
### Use spinlock even in memory implementation (unchanged)
In actual use cases, users may cancel requests. `sync.Mutex` will block
the goroutine until the lock is acquired even if the request is
canceled. And the spinlock is more suitable for this scenario since it's
possible to give up the lock acquisition.
Although the spinlock consumes more CPU resources, I think it's
acceptable in most cases.
### Do not expose the mutex to callers (unchanged)
If we expose the mutex to callers, it's possible for callers to reuse
the mutex, which causes more complexity.
For example:
```go
lock := GetLocker(key)
lock.Lock()
// ...
// even if the lock is unlocked, we cannot GC the lock,
// since the caller may still use it again.
lock.Unlock()
lock.Lock()
// ...
lock.Unlock()
// callers have to GC the lock manually.
RemoveLocker(key)
```
That's why
https://github.com/go-gitea/gitea/pull/31813#discussion_r1721200549
In this PR, we only expose `ReleaseFunc` to callers. So callers just
need to call `ReleaseFunc` to release the lock, and do not need to care
about the lock's lifecycle.
```go
release, err := locker.Lock(ctx, key)
if err != nil {
return err
}
// ...
release()
// if callers want to lock again, they have to re-acquire the lock.
release, err := locker.Lock(ctx, key)
// ...
```
In this way, it's also much easier for redis implementation to extend
the mutex automatically, so that callers do not need to care about the
lock's lifecycle. See also
https://github.com/go-gitea/gitea/pull/31813#discussion_r1722659743
### Use "release" instead of "unlock" (unchanged)
For "unlock", it has the meaning of "unlock an acquired lock". So it's
not acceptable to call "unlock" when failed to acquire the lock, or call
"unlock" multiple times. It causes more complexity for callers to decide
whether to call "unlock" or not.
So we use "release" instead of "unlock" to make it clear. Whether the
lock is acquired or not, callers can always call "release", and it's
also safe to call "release" multiple times.
But the code DO NOT expect callers to not call "release" after acquiring
the lock. If callers forget to call "release", it will cause resource
leak. That's why it's always safe to call "release" without extra
checks: to avoid callers to forget to call it.
### Acquired locks could be lost, but the callers shouldn't stop
Unlike `sync.Mutex` which will be locked forever once acquired until
calling `Unlock`, for distributed lock, the acquired lock could be lost.
For example, the caller has acquired the lock, and it holds the lock for
a long time since auto-extending is working for redis. However, it lost
the connection to the redis server, and it's impossible to extend the
lock anymore.
In #31908, it will cancel the context to make the operation stop, but
it's not safe. Many operations are not revert-able. If they have been
interrupted, then the instance goes corrupted. So `Lock` won't return
`ctx` anymore in this PR.
### Multiple ways to use the lock
1. Regular way
```go
release, err := Lock(ctx, key)
if err != nil {
return err
}
defer release()
// ...
```
2. Early release
```go
release, err := Lock(ctx, key)
if err != nil {
return err
}
defer release()
// ...
// release the lock earlier
release()
// continue to do something else
// ...
```
3. Functional way
```go
if err := LockAndDo(ctx, key, func(ctx context.Context) error {
// ...
return nil
}); err != nil {
return err
}
```
To help #31813, but do not replace it, since this PR just introduces the
new module but misses some work:
- New option in settings. `#31813` has done it.
- Use the locks in business logic. `#31813` has done it.
So I think the most efficient way is to merge this PR first (if it's
acceptable) and then finish #31813.
## Design principles
### Use spinlock even in memory implementation
In actual use cases, users may cancel requests. `sync.Mutex` will block
the goroutine until the lock is acquired even if the request is
canceled. And the spinlock is more suitable for this scenario since it's
possible to give up the lock acquisition.
Although the spinlock consumes more CPU resources, I think it's
acceptable in most cases.
### Do not expose the mutex to callers
If we expose the mutex to callers, it's possible for callers to reuse
the mutex, which causes more complexity.
For example:
```go
lock := GetLocker(key)
lock.Lock()
// ...
// even if the lock is unlocked, we cannot GC the lock,
// since the caller may still use it again.
lock.Unlock()
lock.Lock()
// ...
lock.Unlock()
// callers have to GC the lock manually.
RemoveLocker(key)
```
That's why
https://github.com/go-gitea/gitea/pull/31813#discussion_r1721200549
In this PR, we only expose `ReleaseFunc` to callers. So callers just
need to call `ReleaseFunc` to release the lock, and do not need to care
about the lock's lifecycle.
```go
_, release, err := locker.Lock(ctx, key)
if err != nil {
return err
}
// ...
release()
// if callers want to lock again, they have to re-acquire the lock.
_, release, err := locker.Lock(ctx, key)
// ...
```
In this way, it's also much easier for redis implementation to extend
the mutex automatically, so that callers do not need to care about the
lock's lifecycle. See also
https://github.com/go-gitea/gitea/pull/31813#discussion_r1722659743
### Use "release" instead of "unlock"
For "unlock", it has the meaning of "unlock an acquired lock". So it's
not acceptable to call "unlock" when failed to acquire the lock, or call
"unlock" multiple times. It causes more complexity for callers to decide
whether to call "unlock" or not.
So we use "release" instead of "unlock" to make it clear. Whether the
lock is acquired or not, callers can always call "release", and it's
also safe to call "release" multiple times.
But the code DO NOT expect callers to not call "release" after acquiring
the lock. If callers forget to call "release", it will cause resource
leak. That's why it's always safe to call "release" without extra
checks: to avoid callers to forget to call it.
### Acquired locks could be lost
Unlike `sync.Mutex` which will be locked forever once acquired until
calling `Unlock`, in the new module, the acquired lock could be lost.
For example, the caller has acquired the lock, and it holds the lock for
a long time since auto-extending is working for redis. However, it lost
the connection to the redis server, and it's impossible to extend the
lock anymore.
If the caller don't stop what it's doing, another instance which can
connect to the redis server could acquire the lock, and do the same
thing, which could cause data inconsistency.
So the caller should know what happened, the solution is to return a new
context which will be canceled if the lock is lost or released:
```go
ctx, release, err := locker.Lock(ctx, key)
if err != nil {
return err
}
defer release()
// ...
DoSomething(ctx)
// the lock is lost now, then ctx has been canceled.
// Failed, since ctx has been canceled.
DoSomethingElse(ctx)
```
### Multiple ways to use the lock
1. Regular way
```go
ctx, release, err := Lock(ctx, key)
if err != nil {
return err
}
defer release()
// ...
```
2. Early release
```go
ctx, release, err := Lock(ctx, key)
if err != nil {
return err
}
defer release()
// ...
// release the lock earlier and reset the context back
ctx = release()
// continue to do something else
// ...
```
3. Functional way
```go
if err := LockAndDo(ctx, key, func(ctx context.Context) error {
// ...
return nil
}); err != nil {
return err
}
```
When opening a repository, it will call `ensureValidRepository` and also
`CatFileBatch`. But sometimes these will not be used until repository
closed. So it's a waste of CPU to invoke 3 times git command for every
open repository.
This PR removed all of these from `OpenRepository` but only kept
checking whether the folder exists. When a batch is necessary, the
necessary functions will be invoked.
fix#23668
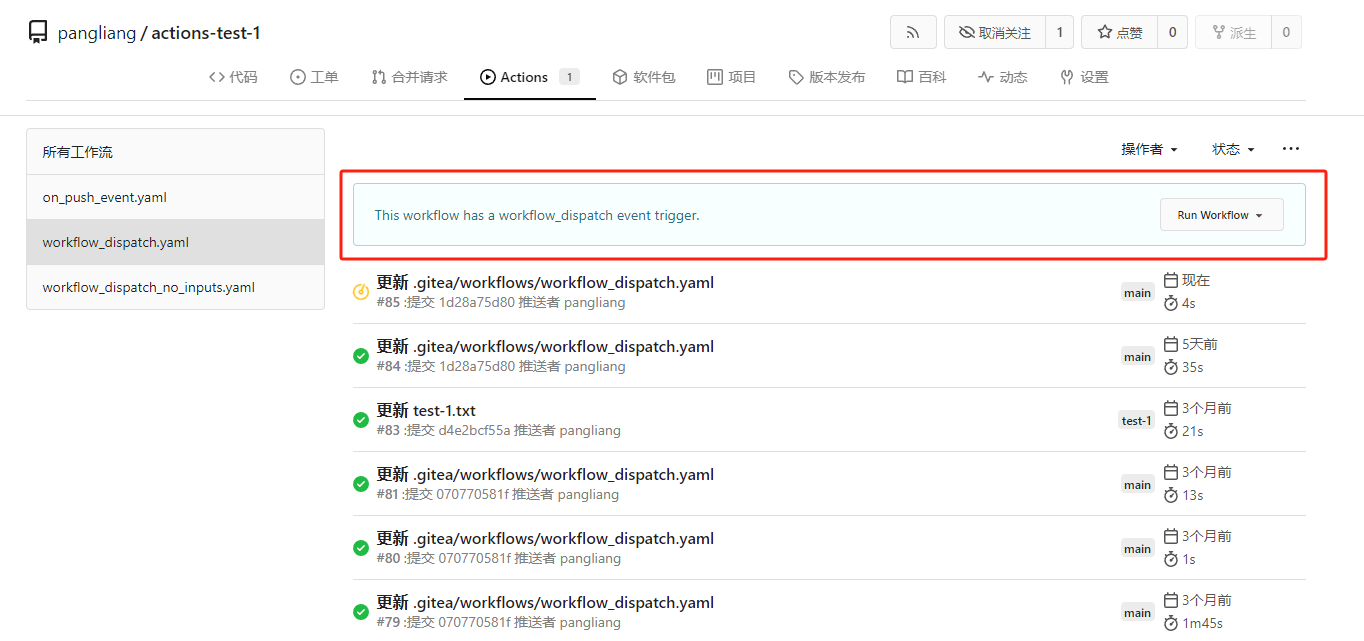
My plan:
* In the `actions.list` method, if workflow is selected and IsAdmin,
check whether the on event contains `workflow_dispatch`. If so, display
a `Run workflow` button to allow the user to manually trigger the run.
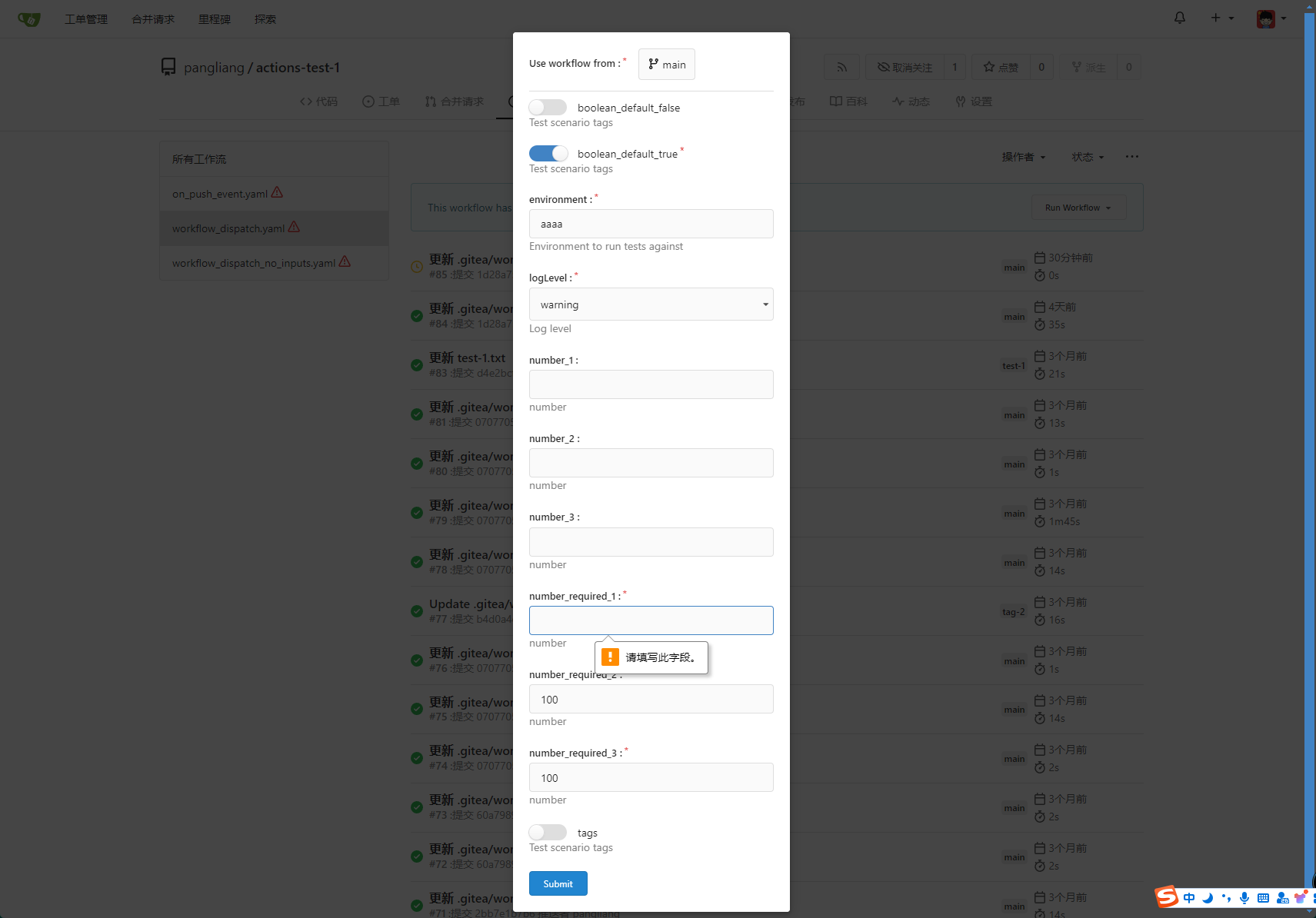
* Providing a form that allows users to select target brach or tag, and
these parameters can be configured in yaml
* Simple form validation, `required` input cannot be empty
* Add a route `/actions/run`, and an `actions.Run` method to handle
* Add `WorkflowDispatchPayload` struct to pass the Webhook event payload
to the runner when triggered, this payload carries the `inputs` values
and other fields, doc: [workflow_dispatch
payload](https://docs.github.com/en/webhooks/webhook-events-and-payloads#workflow_dispatch)
Other PRs
* the `Workflow.WorkflowDispatchConfig()` method still return non-nil
when workflow_dispatch is not defined. I submitted a PR
https://gitea.com/gitea/act/pulls/85 to fix it. Still waiting for them
to process.
Behavior should be same with github, but may cause confusion. Here's a
quick reminder.
*
[Doc](https://docs.github.com/en/actions/using-workflows/events-that-trigger-workflows#workflow_dispatch)
Said: This event will `only` trigger a workflow run if the workflow file
is `on the default branch`.
* If the workflow yaml file only exists in a non-default branch, it
cannot be triggered. (It will not even show up in the workflow list)
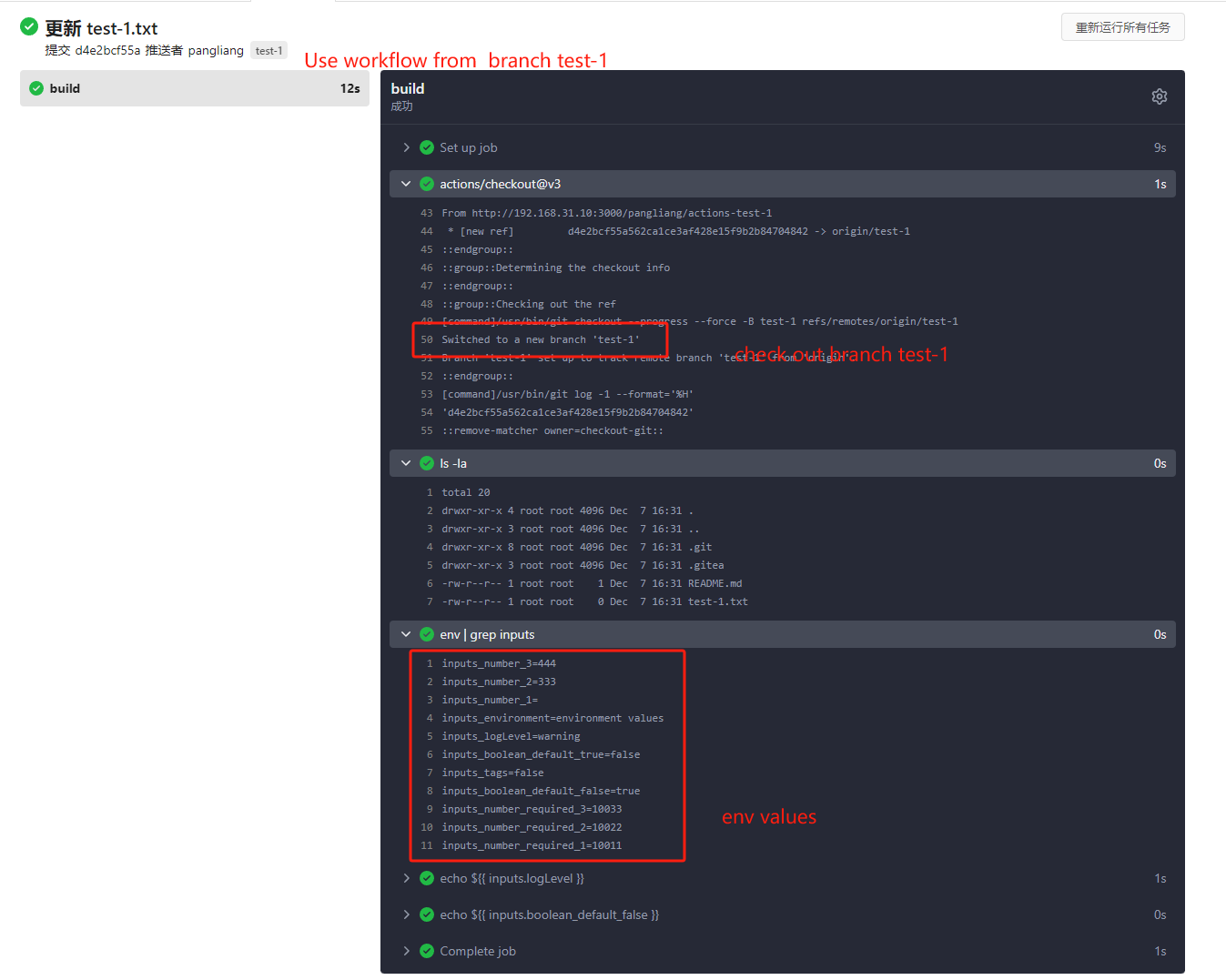
* If the same workflow yaml file exists in each branch at the same time,
the version of the default branch is used. Even if `Use workflow from`
selects another branch
```yaml
name: Docker Image CI
on:
workflow_dispatch:
inputs:
logLevel:
description: 'Log level'
required: true
default: 'warning'
type: choice
options:
- info
- warning
- debug
tags:
description: 'Test scenario tags'
required: false
type: boolean
boolean_default_true:
description: 'Test scenario tags'
required: true
type: boolean
default: true
boolean_default_false:
description: 'Test scenario tags'
required: false
type: boolean
default: false
environment:
description: 'Environment to run tests against'
type: environment
required: true
default: 'environment values'
number_required_1:
description: 'number '
type: number
required: true
default: '100'
number_required_2:
description: 'number'
type: number
required: true
default: '100'
number_required_3:
description: 'number'
type: number
required: true
default: '100'
number_1:
description: 'number'
type: number
required: false
number_2:
description: 'number'
type: number
required: false
number_3:
description: 'number'
type: number
required: false
env:
inputs_logLevel: ${{ inputs.logLevel }}
inputs_tags: ${{ inputs.tags }}
inputs_boolean_default_true: ${{ inputs.boolean_default_true }}
inputs_boolean_default_false: ${{ inputs.boolean_default_false }}
inputs_environment: ${{ inputs.environment }}
inputs_number_1: ${{ inputs.number_1 }}
inputs_number_2: ${{ inputs.number_2 }}
inputs_number_3: ${{ inputs.number_3 }}
inputs_number_required_1: ${{ inputs.number_required_1 }}
inputs_number_required_2: ${{ inputs.number_required_2 }}
inputs_number_required_3: ${{ inputs.number_required_3 }}
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- run: ls -la
- run: env | grep inputs
- run: echo ${{ inputs.logLevel }}
- run: echo ${{ inputs.boolean_default_false }}
```
---------
Co-authored-by: TKaxv_7S <954067342@qq.com>
Co-authored-by: silverwind <me@silverwind.io>
Co-authored-by: Denys Konovalov <kontakt@denyskon.de>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Fix#31395
This regression is introduced by #30273. To find out how GitHub handles
this case, I did [some
tests](https://github.com/go-gitea/gitea/issues/31395#issuecomment-2278929115).
I use redirect in this PR instead of checking if the corresponding `.md`
file exists when rendering the link because GitHub also uses redirect.
With this PR, there is no need to resolve the raw wiki link when
rendering a wiki page. If a wiki link points to a raw file, access will
be redirected to the raw link.
Fix#31271.
When gogit is enabled, `IsObjectExist` calls
`repo.gogitRepo.ResolveRevision`, which is not correct. It's for
checking references not objects, it could work with commit hash since
it's both a valid reference and a commit object, but it doesn't work
with blob objects.
So it causes #31271 because it reports that all blob objects do not
exist.